
Premessa
Questo articolo è stato scritto da Adan Fabio autore in METALTECH . Io ho solo tradotto questo bell’articolo per chi non mastica l’inglese.
la versione originale la potete visionare qui : https://hackaday.com/2018/01/15/spectre-and-meltdown-how-cache-works/
Buona lettura a tutti.
SPECTRE E MELTDOWN
L’anno finora è stato riempito con notizie di Spectre e Meltdown. Questi exploit sfruttano funzionalità come l’esecuzione speculativa e il tempo di accesso alla memoria. Quello che hanno in comune è il fatto che tutti i processori moderni usano la cache per accedere più rapidamente alla memoria. Abbiamo tutti sentito parlare di cache, ma cosa è esattamente, e in che modo consente ai nostri computer di funzionare più velocemente?
Nei termini più semplici, la cache è una memoria veloce. I computer dispongono di due sistemi di archiviazione: memoria principale (RAM) e memoria secondaria (disco rigido, SSD). Dal punto di vista del processore, il caricamento dei dati o delle istruzioni dalla RAM è lento: la CPU deve attendere e non eseguire nulla per 100 cicli o più mentre i dati vengono caricati. Il caricamento dal disco è ancora più lento; milioni di cicli sono sprecati. La cache è una piccola quantità di memoria molto veloce che viene utilizzata per contenere dati e istruzioni comunemente utilizzati. Ciò significa che il processore deve solo attendere che la cache venga caricata una volta. Dopo ciò, i dati sono accessibili senza aspettare.
Un’analogia comune (sebbene obsoleta) per la cache utilizza i libri per rappresentare i dati: se avevi bisogno di un libro specifico per cercare un’informazione importante, dovresti prima controllare i libri sulla tua scrivania (memoria cache). Se il tuo libro non è lì, allora vai ai libri nei tuoi scaffali (RAM). Se la ricerca è risultata vuota, ti dirigerai verso la biblioteca locale (disco rigido) e controllerai il libro. Una volta tornato a casa, manterrai il libro sulla tua scrivania per un rapido riferimento – non immediatamente lo rimetterai negli scaffali della biblioteca. Ecco come funziona la lettura della cache.
Cache è un immobile costoso
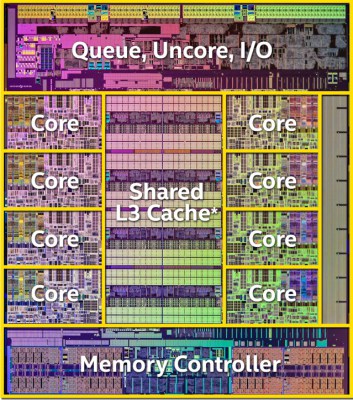
Diagramma Intel Haswell. Nota quanto spazio immobiliare viene utilizzato dalla cache L3 e dal controller di memoria.
I primi computer funzionavano così lentamente che la cache in realtà non importava. La memoria del core era molto veloce quando la velocità della CPU era misurata in kHz. La prima cache di dati è stata utilizzata nel modello 85 System / 360 IBM, rilasciato nel 1968. La documentazione di IBM richiedeva operazioni di memoria da ¼ a ⅓ meno tempo rispetto a un sistema senza cache di dati.
Ora la domanda ovvia è se la cache è più veloce, perché non fare tutta la memoria fuori dalla cache? Ci sono due risposte a questo. Innanzitutto, la cache è più costosa della memoria principale. Generalmente, la cache è costruita con RAM statica, che è molto più costosa della RAM dinamica utilizzata nella memoria principale. La seconda risposta è posizione, posizione, posizione. Con i processori in esecuzione a diversi GHz, la cache ora deve essere sullo stesso pezzo di silicio con il processore stesso. L’invio dei segnali su tracce PCB richiederebbe troppo tempo.
Il core della CPU in genere non conosce o si preoccupa della cache. Tutta la gestione della casa e della cache è gestita dalla Memory Management Unit (MMU) o dal controller della cache. Si tratta di sistemi logici complessi che devono operare rapidamente per mantenere la CPU carica di dati e istruzioni.
Direct Mapped Cache
 La forma più semplice di una cache è chiamata cache mappata diretta. Mappatura diretta significa che ogni posizione di memoria esegue il mapping su una sola posizione della cache. Nel diagramma, ci sono 4 slot di cache. Ciò significa che l’indice di cache 0 potrebbe contenere l’indice di memoria 0,4,8 e così via. Dal momento che un blocco di cache può contenere una qualsiasi di più posizioni di memoria, il controller di cache ha bisogno di un modo per sapere quale memoria è effettivamente nella cache. Per gestire questo, ogni blocco cache ha un tag, che contiene i bit superiori dell’indirizzo di memoria attualmente memorizzato nella cache.
La forma più semplice di una cache è chiamata cache mappata diretta. Mappatura diretta significa che ogni posizione di memoria esegue il mapping su una sola posizione della cache. Nel diagramma, ci sono 4 slot di cache. Ciò significa che l’indice di cache 0 potrebbe contenere l’indice di memoria 0,4,8 e così via. Dal momento che un blocco di cache può contenere una qualsiasi di più posizioni di memoria, il controller di cache ha bisogno di un modo per sapere quale memoria è effettivamente nella cache. Per gestire questo, ogni blocco cache ha un tag, che contiene i bit superiori dell’indirizzo di memoria attualmente memorizzato nella cache.
Il controller della cache deve anche sapere se la cache contiene effettivamente dati o spazzatura utilizzabili. Quando il processore si avvia per la prima volta, tutte le posizioni della cache saranno casuali. Sarebbe davvero brutto se alcuni di questi dati casuali venissero usati accidentalmente in un calcolo. Questo è gestito con un bit valido. Se il bit valido è impostato su 0, la posizione della cache contiene dati non validi e viene ignorata. Se il bit è 1, i dati della cache sono validi e il controller della cache lo utilizzerà. Il bit valido viene forzato a zero all’accensione del processore e può essere cancellato ogni volta che il controller della cache deve invalidare la cache.
Scrivere in cache
Finora ho coperto gli accessi in lettura usando la cache, ma per quanto riguarda le scritture? Il controller della cache deve essere sicuro che tutte le modifiche apportate alla memoria nella cache vengano eseguite anche nella RAM prima che la cache venga sovrascritta da qualche nuovo accesso alla memoria. Ci sono due modi fondamentali per farlo. Il primo è scrivere memoria ogni volta che si scrive la cache. Questa è chiamata cache write-through. Il write-through è sicuro ma viene fornito con una penalità di velocità. Le letture sono veloci ma scrivono alla velocità più bassa della memoria principale. Il sistema più popolare è chiamato cache write-back. In un sistema di write-back, le modifiche vengono memorizzate nella cache fino a quando la posizione della cache sta per essere sovrascritta. Il controller della cache deve sapere se è successo, quindi un altro bit chiamato dirty bit viene aggiunto alla cache.
I dati cache hanno bisogno di tutti questi dati di manutenzione – il tag, il bit valido, il bit dirty – memorizzati nella memoria cache ad alta velocità, che aumenta il costo complessivo del sistema cache.
Cache associativa
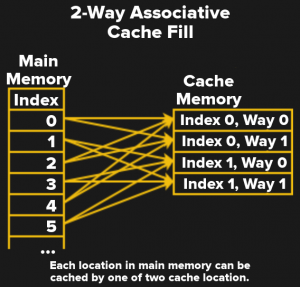
Una cache mappata diretta accelera gli accessi alla memoria, ma la mappatura uno-a-uno della memoria nella cache è relativamente inefficiente. È molto più efficiente consentire l’archiviazione di dati e istruzioni in più di una posizione.
Una cache completamente associativa consente proprio questo: qualsiasi posizione di memoria può essere archiviata in qualsiasi posizione cache. Ciò significa anche che la cache deve essere cercata su ogni accesso alla memoria. Una funzione di ricerca come questa viene eseguita con un comparatore hardware. Un comparatore come questo richiederebbe un sacco di porte logiche e mangerà una grande area fisica sul chip. Il mezzo felice è un set di cache associative. Il diagramma mostra una cache associativa a due vie. Ciò significa che qualsiasi posizione di memoria può andare in una delle due posizioni della cache. Ciò mantiene il comparatore hardware relativamente semplice e veloce. Ad esempio, la cache di livello 3 di Intel Core i7-8700K è associativa a 16 vie.
Memoria virtuale
All’inizio, i computer eseguivano un programma alla volta. Un programmatore ha avuto accesso all’intera memoria del sistema e ha dovuto gestire il modo in cui tale memoria è stata utilizzata. Se il suo programma fosse più grande dell’intero spazio RAM del sistema, spetterebbe al programmatore scambiare le sezioni dentro o fuori a seconda delle necessità. Immagina di dover controllare se printf () viene caricato in memoria ogni volta che vuoi stampare qualcosa.
La memoria virtuale è il modo in cui un sistema operativo lavora direttamente con l’MMU del processore per far fronte a questo. La memoria principale è suddivisa in pagine. Ogni pagina viene scambiata come è necessario. Oggigiorno, con la memoria economica, non dobbiamo preoccuparci tanto di scambiare su disco. Tuttavia, la memoria virtuale è ancora di vitale importanza per alcuni degli altri vantaggi che offre.
La memoria virtuale consente al sistema operativo di eseguire molti programmi contemporaneamente: ogni programma ha il proprio spazio di indirizzamento virtuale, che viene quindi mappato alle pagine nella memoria fisica. Questa mappatura è memorizzata nella tabella delle pagine, che vive nella RAM. La tabella delle pagine è così importante che ottiene la propria cache speciale chiamata Translation Look-aside Buffer, o TLB.
L’MMU e l’hardware di memoria virtuale funzionano anche con il sistema operativo per rafforzare la protezione della memoria: non lasciare che i programmi leggano o modificino a vicenda lo spazio di memoria, e non lasciare che nessuno lavori con il kernel. Questa è la protezione che viene aggirata dagli attacchi Spectre e Meltdown.
Nel mondo reale
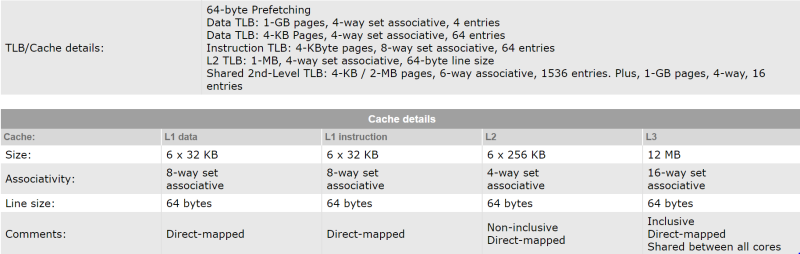
Come puoi vedere, anche i sistemi di cache relativamente semplici possono essere difficili da seguire. In un moderno processore come Intel i7-8700K, ci sono più livelli di cache , alcuni indipendenti, altri condivisi tra i core della CPU. Esistono anche i motori di esecuzione speculativi, che estraggono i dati che potrebbero essere utilizzati dalla memoria nella cache prima che un dato core sia pronto per questo. Quel motore è la chiave di Meltdown.
Sia Spectre che Meltdown usano la cache in un attacco basato sui tempi. Poiché la memoria cache è molto più veloce da accedere, un utente malintenzionato può misurare il tempo di accesso per determinare se la memoria proviene dalla RAM o dalla cache. Quella informazione di temporizzazione può quindi essere utilizzata per leggere effettivamente i dati nella memoria. Questo è il motivo per cui una patch Javascript è stata inviata ai browser due settimane fa. Quella patch rende il timing integrato di Javascript un po ‘meno accurato , quanto basta per renderli inutili nel misurare il tempo di accesso alla memoria che salvaguarda gli exploit basati sul browser per queste vulnerabilità.
Il semplice metodo istintivo per cercare di mitigare Spectre e Meltdown è disabilitare le cache. Ciò renderebbe i nostri sistemi informatici incredibilmente lenti rispetto alle velocità a cui siamo abituati. Le patch che vengono lanciate non sono così estreme, ma cambiano il modo in cui la CPU lavora con la cache, in particolare sullo spazio utente per gli switch di contesto dello spazio del kernel.
Datapath e cache della CPU
La moderna progettazione di datapath e cache della CPU è un compito incredibilmente complesso. I produttori di processori hanno accumulato anni di dati simulando e analizzando statisticamente il modo in cui i processori spostano i dati per rendere i sistemi rapidi e affidabili. Le modifiche a qualcosa come il microcodice del processore vengono eseguite solo quando assolutamente necessario e solo dopo migliaia di ore di test. Un cambio di fucile fatto in fretta (sì, sei mesi è un momento di punta) come le attuali patch Intel e AMD sicuramente avrà alcuni problemi – e questo è esattamente quello che stiamo vedendo con grandi colpi di performance e crash. Il lato software della correzione come l’ isolamento della tabella delle pagine del kernel può forzare lo svuotamento del TLBs, che ha anche grandi successi nelle prestazioni per le applicazioni che effettuano chiamate frequenti al sistema operativo. Questo spiega alcuni dei motivi per cui l’impatto delle modifiche dipende in modo specifico dall’applicazione. In sostanza, siamo tutti beta tester.
C’è comunque un lato positivo. La speranza è che con più tempo per la ricerca e il collaudo da parte dei produttori di chip e dei fornitori di software, le modifiche necessarie saranno meglio comprese e verranno rilasciate patch migliori.
Cioè, finché non viene trovato il prossimo vettore di attacco.
Scrivi un commento
Devi accedere, per commentare.